Expertise transformation durable de l'habitat
Grâce à ses experts internes et à son réseau de partenaires, namR a développé une expertise pointue et transverse en transformation écologique de l’habitat
Expertise en analyse d'images
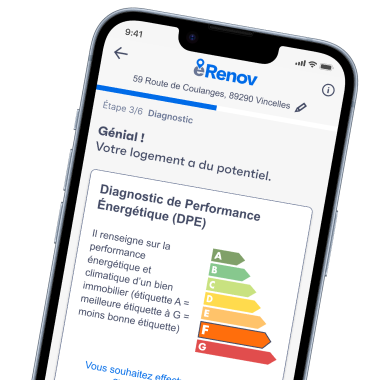
namR exploite le meilleur du big data (open data ou données partenaires) pour décrire des millions de bâtiments, leur morphologie, leur environnement et leur contexte
Expertise en machine learning
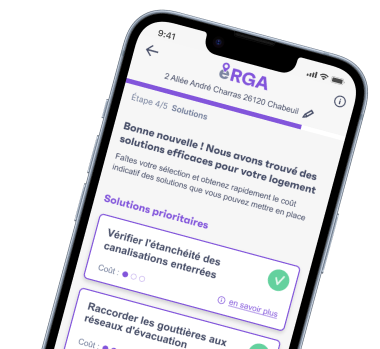
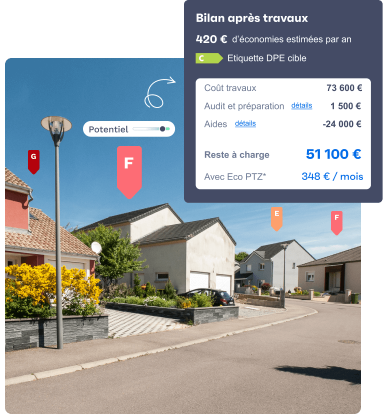
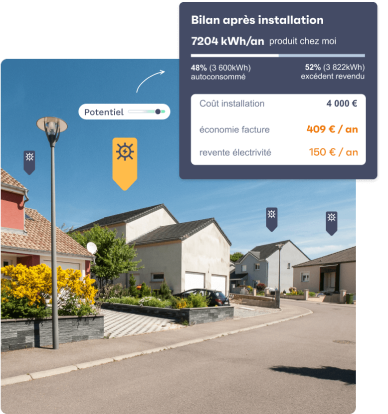
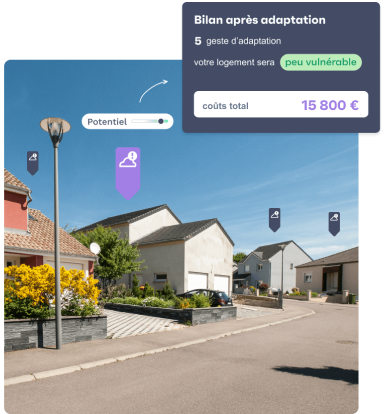
namR fabrique des algorithmes pour définir la meilleure solution d’atténuation ou d’adaptation, de façon personnalisée pour chaque habitation.

"Les simulateurs en ligne sont très mono travaux ou trop complexes; namR répond à notre enjeu d'avoir un simulateur court et facile à remplir"
BNP Personal Finance